
Short Reach Optical Interconnect (SROI) White Paper Released
(Rethinking CPU to GPU, Memory and I/O Interconnect)
Earlier this month, the Short Reach Optical Interconnect (SROI) workstream within the Open Compute Project’s Future Technologies Initiative released a white paper collection covering a series of use case challenge and technology opportunities originally discussed in the October 2023 OCP Future Technologies Initiative Workshops at OCP Global Summit.
The work represents the effort of over a dozen companies and several dozen subject matter experts from across the OCP Community, with the goal of outlining what is needed and what might be possible in the use of optical interconnects over short distances for higher-speed and lower-power communication among computing, memory, and storage components.
Everyone is encouraged to take a closer look at the full white paper, linked online at
Everyone is also encouraged to share this overview with your colleagues at your organization and encourage them to get involved with the initiative, by signing up to the mailing list and joining the meetings of the group (open membership):
https://www.opencompute.org/projects/short-reach-optical-interconnect
Highlighting just a small number of the key points made in the white paper here will attempt to give a concrete flavor of the challenges and the opportunities that are discussed within the SROI FTI Workstream.
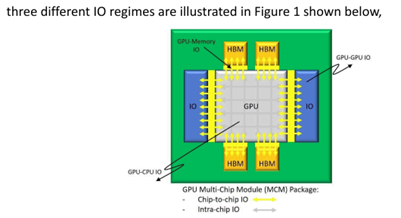
These first images illustrate the variety of high-speed connections needed, including CPU or GPU to high-bandwidth memory (HBM); GPU-to-GPU; GPU-to-CPU; and GPU-to-IO all of which are under pressure in the most demanding data center workloads. The image shows an idealized diagram of the various connectivity needs (left), and a currently shipping GPU chip with the HBM sections clearly visible (right).
 |
 |
The complexity of potential applications is well illustrated here, because applications may require tightly coupled communication among:
- CPU for general-purpose computation & orchestration
- GPU or other special-purpose computation
- memory elements, local & remote
- storage elements, local & remote
- off-chip clustering, to other GPUs or CPUs
Ideally performance of all these links is highest bandwidth and lowest latency - to allow tight coupling with maximum flexibility as nodes are aggregated into clusters for any particular set of computations.
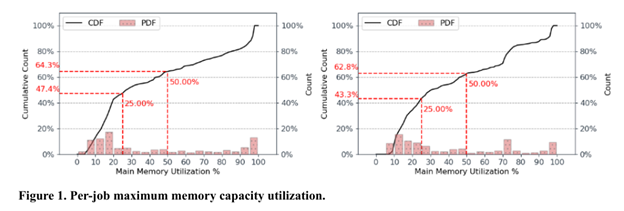
The potential performance gaps are made clear by two sets of data in a white paper section covering measurements of accelerated workloads run on a large-scale engineering cluster today.
The charts below show main memory utilization of CPU nodes (left) and GPU nodes (right) for a range of measured workloads (x axis is cumulative count of workloads). Both charts indicate a small number of workloads using the full memory size - red bars at far right of each chart - but also a large fraction of jobs using only a small fraction of the available memory - mass of red bars to the left in both charts. This means that these nodes are over-designed for these workloads, since memory is available but not being utilized.
A similar limitation is shown in the next two charts, which give GPU utilization (left) and GPU/HBM memory utilization (right) where underlying GPU utilization is at 100% for a plurality of jobs - red bar at the far right of the left chart - but HBM utilization is almost uniformly low - red bars in the right chart.
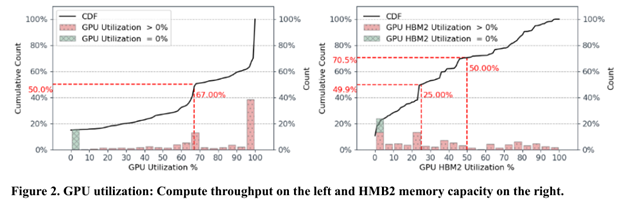
In this case again, expensive memory resources are available, but left underutilized the practice. One approach to overcome such limitations is to centralize the memory components in order to allow them to be shared with increased utilization. This requires some interconnect fabric, and immediately introduces potentially lower bandwidth and higher latency between compute and memory components.
The sensitivity of application performance to small changes in interconnect latency is shown in the figure below where a change from 25 nanoseconds (ns) to even 35 ns of added latency can slow application performance by half (tall yellow slowdown bars).
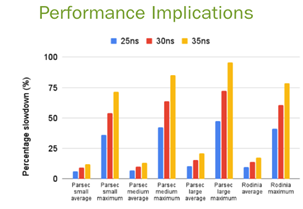
Such connections would be made with electrical wires today, leading to a second challenge after performance - power consumption.
The marked increase in networking traffic within data centers shows a distressing trend even before finer-grained resource sharing such as the above are added. The rapid growth of machine-to-machine network traffic (left) increases aggregate bandwidth demand, even as cost per bandwidth continues to decline (right). This means that total traffic, and therefore total power consumption, increases significantly (red pie slice).
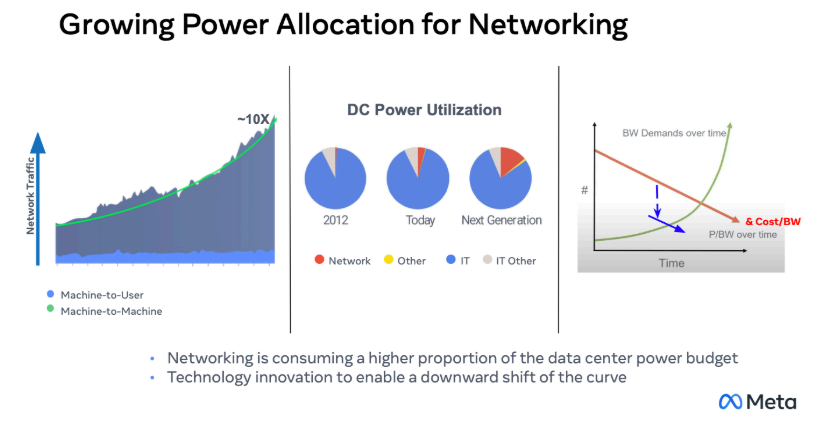
As outlined in great depth in the white paper sections, the solution of optical connections addresses both issues - bandwidth is kept high, latency low, and power consumption is better managed than when electrical connectivity is used. Optical interconnection points are included inside the compute substrates, so that memory as well as chip-to-chip interconnection proceeds with optical rather than electrical signaling.
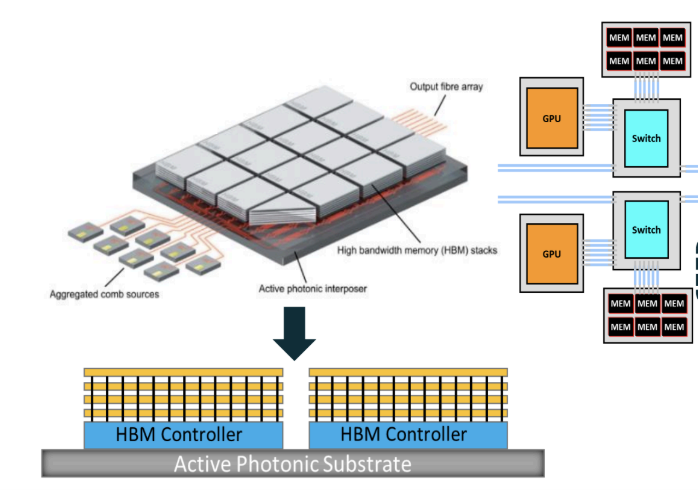
The above is a conceptual diagram, but practical devices are being prototyped already, as shown below.
 |
 |
There are many design and deployment challenges to realizing these technology proposals, with many iterations and learnings still ahead. Almost certainly a suite of solutions will be needed, addressing the variety of use cases.
Please take a look at the full white paper to better understand what is only briefly overviewed here.
Also please join, or encourage your networking colleagues to join, the initiative by signing up to the mailing list and attending the meetings of the FTi SROI Workstream:
https://www.opencompute.org/projects/short-reach-optical-interconnect
An exciting new technology area - being developed in open collaboration - with many promising proposals and avenues toward comprehensive solutions that will eventually be used across the industry.